
Hello! I am Ihor Dodukh, Automation QA Lead. I have been working in quality assurance since 2015, mainly dealing with automation. During my career, I have completed 10+ projects from scratch, and I am currently working at P2H, an international company with Ukrainian roots, where I mentor a team of seven automation engineers.
In this article, I will review ten typical problems and errors that might arise in the automation process—especially those that beginners struggle with. If you are aware of these issues, avoiding them in your work will be easier.
A small disclaimer: I co-authored this article with Kateryna Starokoltseva-Skrypnyk, copywriter and editor. And now, let us dive right in.
First things first: processes and infrastructure
Automation is an umbrella term for a whole range of processes and infrastructure elements. It all depends on the team that develops and supports the project, as well as the capabilities of the project itself.
Someone is ready to splash out on enterprise solutions, including customized environments with infrastructure, frameworks, integrated features, reporting, logging, and cloud storage connections. Others prefer traditional solutions and approaches where automated testing infrastructure is configured manually, assembling every component, like puzzle pieces, to fit the customer’s needs.
Another approach is using automated testing tools that require little to no coding, allowing you to write simple tests quickly.
Each approach has its specifics that must be considered before setting up automated testing. If you doubt your abilities, it’s best to contact a professional with the relevant expertise to analyze your needs and infrastructure capabilities and check whether the project is ready for automation.So, what is infrastructure, then? Infrastructure is a set of systems and services empowering automated testing. You must configure the infrastructure properly, so the automated tests run well.
For example, my team and I follow this scheme:
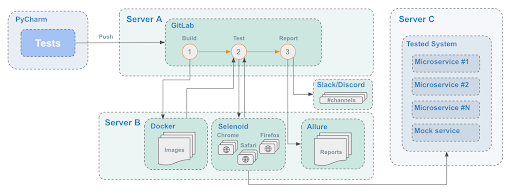
Tests are written in Python using the PyTest framework + Selenium. Then, they’re pushed to GitLab, where a pipeline is triggered. The pipeline forms in three consequent steps:
- The tests are collected in a Docker image to be run in an isolated environment.
- The tests are run, and a browser session is created in Selenoid (Selenium Grid). The tests start to interact with the system being tested through the browser. The test results are collected as job artifacts.
- The test results are retrieved from the artifacts, processed, and sent to the Allure report to be posted on the Slack channel.
Now let’s move on straight to the most common challenges and errors that come up when working with automated tests.
10 typical problems and errors
Running tests locally
The first thing QA automation engineers usually do when they start working with automated tests is run them locally. This is an excellent option for training purposes, but you’d better not do it for a client project. Your computer’s capabilities are usually too limited to run things this way. Poor connection, insufficient memory, and the need to run other apps simultaneously can all affect the test execution.
Two options can improve the situation. One of them—not perfect but fully functional—is to run tests in a repository on a separate server.
The best option, though, is containerization. We work with Docker + Kubernetes: as isolated environments, they provide consistent and stable outcomes. The tests are run independently, as if each of them is playing in its sandbox.
I also recommend using Selenium Grid—a fantastic solution that helps you avoid working with local browsers.
Insufficient resources (RAM, CPU) to work with browsers
When planning a resource-intensive activity like working with browsers, it’s crucial to perform a test run at the planning stage and see whether you have enough resources to ensure the stable work of Selenium Grid. It’s best to run peak load tests, engaging all available browsers, and assess the system performance this way.
Settings limitations of the testing system
Automated tests run much faster than those performed by a regular user, producing a certain load on the system. Therefore, some components might not have enough time to process requests as quickly as needed or encounter limitations.
In particular, the number of database or server connections might be limited. This parameter is often ignored in test environments, being set to the default value. But when there are many tests—especially in the case of parallel testing—the number of database or server requests runs high. Some tests may simply fail as they’re reaching their processing limit.
Lack of browser instances
When it comes to Selenoid or Selenium Grid, you must properly configure the right number of browser instances. Depending on the settings, an app may use only a specific, limited number of browsers (for example, 5 Chrome or Firefox). We configured one Selenium Grid with 10+ browser instances for several projects. It’s convenient this way, as we work with a big client with a few subprojects, and it makes no sense to maintain multiple Selenium Grids.
You can run a few of these tests. In the case of Selenoid, new tests go into standby mode until the previous session is completed. It’s not as perfect with Selenium Grid, though, since an automated test can fail if there are not enough unused browser instances. So you must calculate the number of instances, considering execution time and peak load.
Poor test architecture
If you plan to run tests in Selenium Grid, you must design the test structure for parallel testing. First, tests must be independent, using unique data for each test. The very framework architecture may accommodate only one test session at a time, so when multiple sessions (API or browser) run, the data gets mixed up, and the test behavior becomes unpredictable.
Browser timeout
Selenium Grid has a specific feature: it automatically terminates idle sessions. So, if you have a habit of setting things up by just copying and pasting code from the Internet, you might accidentally copy parameters that will terminate the browser session after only a minute of idle time.
What’s wrong with that? Some tests follow a scenario where you must wait, say, for two minutes for the necessary data to be pulled up. If that’s the case, your tests will keep crashing. I recommend keeping this in mind and configuring the system specifying an adequate timeout.
Storing old Allure reports
We usually work with dozens of projects, while test reports are quite resource-intensive and include tons of screenshots. The latest twenty to fifty test runs are automatically cached. Your tests may crash just because of this issue. So, I recommend regularly deleting old reports unless the system does it automatically. This habit will save you frustration.
Checking cache is smart even if the tests don’t crash but start running slowly. Most often, it’s the root of the problem. After all, the more test runs are stored, the longer it takes to generate new reports.
Unstructured reports
If anything crashes, go check the report. You need to set up the overall structure to quickly identify the issue. Tests with easy-to-understand tags, a structure matching the requirements of the reporting system (in our case, Allure), test suites, test names, and all dependencies will help you figure out why this particular test crashed and where exactly it happened.
In the report, you must reflect all steps—especially with the checks, as they are the most likely to fail. It’ll also be easier to identify the place of the crash and the probable cause.
Limited access
Tests are usually run on one server, Selenium Grid on another, and the testing system—on yet another. These servers must have unrestricted access to one another. Otherwise, if the servers cannot communicate with each other, the tests will quickly crash, which is not the best thing you want to happen.
I recommend whitelisting the necessary addresses or creating public addresses accessible via VPN.
Poorly thought-out scaling
Sometimes tests slow down during scaling. A good solution, in that case, is to run tests in parallel, keeping in mind the system architecture so that the test data don’t overlap. The test data must be completely independent.
Ideally, the tests should run in parallel as test suites. We have been practicing this quite successfully. You can use all-time favorite test design techniques to cut down the number of tests and their groups.
Wrapping up
As you can see, the automated testing infrastructure can take many forms—just as the needs that automated testing is supposed to solve.
I would recommend starting small—writing short basic tests before setting up servers, cloud solutions, and testing tools. You will find it easier to configure the entire suite step by step after determining what exactly these tests require to function correctly.
Don’t even try to copy-paste infrastructure setup solutions from other projects you can find online, as they might be geared toward completely different needs than your project aims to meet. It’s best to configure things you need one by one rather than roll out a complex solution where every other tool might be redundant.



